Great news, KStreams applications are very easy to scale out of the box! That is of course until things turn sour and you’re left scurrying to figure out why one partition is continuously lagging. When that happens you’ll be thankful for understanding what is happening behind the scenes of streaming API. I’ll try my best to distil this information here.
The first step in understanding KStreams, is understanding Kafka itself. I’m going to assume you already have basic Kafka knowledge. If not, I’d recommend you first read Kafka 101
Let’s start by defining what a topology is.
The Streams Topology
A topology is the architectural schema of your KStreams application in which each message flows through to be processed. The composition of the most basic topology is one source topic, one processor and one output topic. However, that is a boring topology and doesn’t show off how the streaming app can scale, so let’s look at a slightly more complex topology. Let’s add a groupBy { .. } clause that will cause a repartition, so we can see the true parallelism potentials of KStreams.
During initialisation of your KStreams application, you will be able to call a describe function that will output your topology like so:
val sBuilder = StreamsBuilder()
sBuilder.stream("sourceTopic", Consumed.with(StringSerde(), ValueSerde()))
.groupBy { key, value -> KeyValue(value.newKey, value) }
.reduce { _, value2 -> value2 }
.toStream()
.to("targetTopic")
val topology = sBuilder.build()
logger.info(topology.describe())
Which will log this:
Sub-topology: 0
Source: KSTREAM-SOURCE-0000000000 (topics: [sourceTopic])
--> KSTREAM-KEY-SELECT-0000000001
Processor: KSTREAM-KEY-SELECT-0000000001 (stores: [])
--> KSTREAM-FILTER-0000000005
<-- KSTREAM-SOURCE-0000000000
Processor: KSTREAM-FILTER-0000000005 (stores: [])
--> KSTREAM-SINK-0000000004
<-- KSTREAM-KEY-SELECT-0000000001
Sink: KSTREAM-SINK-0000000004 (topic: KSTREAM-AGGREGATE-STATE-STORE-0000000002-repartition)
<-- KSTREAM-FILTER-0000000005
Sub-topology: 1
Source: KSTREAM-SOURCE-0000000006 (topics: [KSTREAM-AGGREGATE-STATE-STORE-0000000002-repartition])
--> KSTREAM-AGGREGATE-0000000003
Processor: KSTREAM-AGGREGATE-0000000003 (stores: [KSTREAM-AGGREGATE-STATE-STORE-0000000002])
--> KTABLE-TOSTREAM-0000000007
<-- KSTREAM-SOURCE-0000000006
Processor: KTABLE-TOSTREAM-0000000007 (stores: [])
--> KSTREAM-SINK-0000000008
<-- KSTREAM-AGGREGATE-0000000003
Sink: KSTREAM-SINK-0000000008 (topic: targetTopic)
<-- KTABLE-TOSTREAM-0000000007
You can copy that into this really useful topology visualisation tool which will output this image:
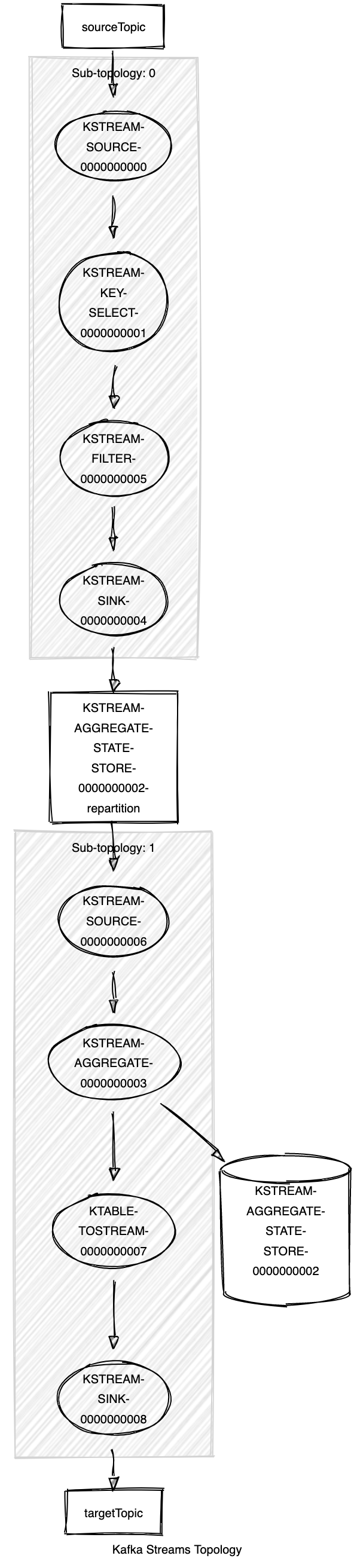
Topology Execution and Parallelism
Let’s go over how the topology is executed in your server.
Source topic partitions are what define the maximum level of parallelism that the application will be capable of. One source partition equates to one task that can be run in parallel. A source topic can be external to the streams application itself (I.e what source topic the stream consumes from) or it can be the result of a repartition like we’ve seen in our example. So if we have one partition on our topic source we will be required to match that with one partition on the repartition topic adding up to two tasks that can be executed in parallel in total.
For each source partition in the topology, there will be one stream task that runs in a KStream thread. It’s not required to have one thread per task as one thread can handle multiple, but to get the most performance out of the application, we can dedicate one thread to each task to prevent streams creating contention amongst tasks to be processed. Figuring out how many tasks the topology requires is easy. It is the sum of all source partitions. One gotcha moment is realising that a source topic can also be a repartition topic. For example, of a groupBy { .. } call and returning a value that is not the same key as previously will result in a repartition. The output of the grouping will be materialised back to the broker and consumed by a task in potentially an independent thread, possibly even a different server. The topology is then said to be comprised of two sub topologies.
You can confirm this by looking at the log output when starting your application
[2020-05-04 16:45:26,859] INFO (org.apache.kafka.streams.processor.internals.StreamThread:351) stream-thread [entities-eb9c0arb-ecad-4rg1-b4e8-715dcf2afee3-StreamThread-1] partition assignment took 100 ms.
current active tasks: [0_0, 0_2, 1_2, 2_2]
current standby tasks: []
previous active tasks: []
In this example we have 1 thread. The current active tasks array has 4 tasks in it, which are all executed on the same thread. The first number indicates the sub-topology number (we have two in our example) and the partition of each topic (again, there are 2 in this example)
Effective Partitioning
Choosing a good key to partition by is absolutely crucial in being able to operate at scale. This is of course not unique to streams, but it is fundamental to streaming architecture. It is crucial to get partitioning right or we risk reducing the overall throughput the application can handle.
Partitioning in Kafka is simple. It’s a (hash of key) modulo (partition count) operation i.e hash(key) % partitionCount. The hard part is finding a key that distributes well across all partitions. For example, if your partitioning key is, say, an account number, that may or may not bode well for you. If traffic across all accounts is even, then you’re in luck - each partition will get an even count of messages thus distributing the load evenly across your fleet of consumers. However, you could have one account which accounts for 80% of your traffic. That would mean that 80% of your traffic goes through one partition! You cannot have multiple instances consuming from the same partition without consuming every single message, so this would create a substantial bottleneck.
This is even further complicated when we consider how partitions are allocated to consumers (tasks) across all available KStream threads in a consumer group.
Task Allocation
The StreamsPartitionAssignor is responsible for divvying up the tasks amongst all the KStream threads in a given consumer group. It is important to understand this class and how this streams specific implementation differs from standard consumer partition allocation algorithms, as it has a direct impact on how you can scale your service. It’s fantastic in keeping an even task count across all threads, but it does have some short comings you’ll need to keep in mind.
The thing to know is that this algorithm currently does not consider the weight of any given task and divvies them up evenly across the consumer group regardless if or not one task will process 80% of all messages.
Now imagine you have a poorly distributed partition load. As we described earlier, this is very possible if you partition by a poor key. Add to this a repartition in your stream like in our example using groupBy {.. }. If one of your source partitions is hot, it will always create a hot partition on the repartitioned topic as well. The bad news is during allocation, it is very possible that one group consumer instance could take all hot partitions creating extra memory and CPU pressure, degrading the overall performance of the entire consumer group!
How do we get around this? Unfortunately, right now the only option we have is to instrument and monitor each deployment and verify each consumer group instance is operating under “normal” conditions. There is however some hope in the future. Looking at this KIP we can see some potential features coming in the future which will attempt to address task weight and a more even load distribution.
Avoid long naming of internal topics
When a consumer group comes up, it first elects a group leader. This leader is responsible for running the aforementioned StreamsPartitionAssignor.
Part of it’s job is to gather the name of each partition of each source and internal topic that is required in the streams topology. It will then produce a record containing all partition allocation information for each kstream thread and send it to the __offsets topic where all other group members will consume from.
The problem here lies in the fact that if you have enough partitions, your message size could easily out-grow the max.message.bytes of the __offsets topic. This will result in a RecordTooLarge exception being thrown and will trigger a rebalance of your consumer group. After rebalance, the same message will be produced and the group will once again enter a state of rebalancing creating a cyclic rebalance cycle.
Once again, this is an issue which was brought to and addressed by Apache in Kafka streams version 2.4.0. Great!
But hold on, that fix just mitigates the problem, it does not remove it entirely. The threshold has greatly been increased, but there is still an upper threshold that your consumer group can hit (And I have still accidentally hit it in production!). So what else can we do?
There is no real elegant solution to this, but we could do one or all of these things:
- Upgrade your KStreams library to at least
2.4.0 - increase the
message.byte.sizelimit of your__offsetstopic. This has some consequences though that will affect the entire Kafka broker, so I would not make this decision lightly. - Reduce character count of internal topic names by explicitly naming internal topics. You can do this in the topology definition
- Evaluate splitting your service in two.
Here is an example of how we can explicitly set a topic name of an materialised internal topic.
Materialized.`as`<Key, Value>(Stores.inMemoryKeyValueStore("topic-name"))
.withKeySerde(Serdes.StringSerde())
.withValueSerde(ReconciliationSerde())
Avoid network operations
This may be obvious to a lot of you, but it’s worth mentioning that I/O will by far be your biggest bottleneck. Typically, I/O is required for some external lookups. You may or may not be able to avoid these lookups, but thankfully, KStreams does provide you a way of doing this lookup without leaving the consumer group instance.
To avail of this, you will need be capable of pre-emptively reading whatever lookup source you require and push it onto a Kafka topic keyed by the same partitioning key and the same partition count as your applications source topic. You can then create an in-memory KTable from the topic.
Conclusion
Kafka streams is a very powerful library which I heartily recommend. However, as we can see there are a few things to keep in mind before blindly deploying this in production.
If you have any questions or comments or feel that I’ve arrived to a questionable or even entirely incorrect conclusion at any point in the article, please leave some below and I’ll be sure to reply!